


- Marking a serious funding in Meta’s AI future, we’re saying two 24k GPU clusters. We’re sharing particulars on the {hardware}, community, storage, design, efficiency, and software program that assist us extract excessive throughput and reliability for varied AI workloads. We use this cluster design for Llama 3 coaching.
- We’re strongly dedicated to open compute and open supply. We constructed these clusters on high of Grand Teton, OpenRack, and PyTorch and proceed to push open innovation throughout the trade.
- This announcement is one step in our formidable infrastructure roadmap. By the top of 2024, we’re aiming to proceed to develop our infrastructure build-out that can embody 350,000 NVIDIA H100 GPUs as a part of a portfolio that can characteristic compute energy equal to almost 600,000 H100s.
To steer in creating AI means main investments in {hardware} infrastructure. {Hardware} infrastructure performs an necessary function in AI’s future. In the present day, we’re sharing particulars on two variations of our 24,576-GPU information heart scale cluster at Meta. These clusters help our present and subsequent era AI fashions, together with Llama 3, the successor to Llama 2, our publicly launched LLM, in addition to AI analysis and improvement throughout GenAI and different areas .
A peek into Meta’s large-scale AI clusters
Meta’s long-term imaginative and prescient is to construct synthetic normal intelligence (AGI) that’s open and constructed responsibly in order that it may be extensively obtainable for everybody to profit from. As we work in the direction of AGI, we now have additionally labored on scaling our clusters to energy this ambition. The progress we make in the direction of AGI creates new merchandise, new AI features for our family of apps, and new AI-centric computing units.
Whereas we’ve had a protracted historical past of constructing AI infrastructure, we first shared particulars on our AI Research SuperCluster (RSC), that includes 16,000 NVIDIA A100 GPUs, in 2022. RSC has accelerated our open and accountable AI analysis by serving to us construct our first era of superior AI fashions. It performed and continues to play an necessary function within the improvement of Llama and Llama 2, in addition to superior AI fashions for purposes starting from pc imaginative and prescient, NLP, and speech recognition, to image generation, and even coding.
Underneath the hood
Our newer AI clusters construct upon the successes and classes discovered from RSC. We centered on constructing end-to-end AI techniques with a serious emphasis on researcher and developer expertise and productiveness. The effectivity of the high-performance community materials inside these clusters, among the key storage selections, mixed with the 24,576 NVIDIA Tensor Core H100 GPUs in every, permit each cluster variations to help fashions bigger and extra complicated than that might be supported within the RSC and pave the best way for developments in GenAI product improvement and AI analysis.
Community
At Meta, we deal with a whole lot of trillions of AI mannequin executions per day. Delivering these providers at a big scale requires a extremely superior and versatile infrastructure. Customized designing a lot of our personal {hardware}, software program, and community materials permits us to optimize the end-to-end expertise for our AI researchers whereas making certain our information facilities function effectively.
With this in thoughts, we constructed one cluster with a distant direct reminiscence entry (RDMA) over converged Ethernet (RoCE) community cloth resolution primarily based on the Arista 7800 with Wedge400 and Minipack2 OCP rack switches. The opposite cluster options an NVIDIA Quantum2 InfiniBand cloth. Each of those options interconnect 400 Gbps endpoints. With these two, we’re capable of assess the suitability and scalability of those different types of interconnect for large-scale training, giving us extra insights that can assist inform how we design and construct even bigger, scaled-up clusters sooner or later. Via cautious co-design of the community, software program, and mannequin architectures, we now have efficiently used each RoCE and InfiniBand clusters for giant, GenAI workloads (together with our ongoing coaching of Llama 3 on our RoCE cluster) with none community bottlenecks.
Compute
Each clusters are constructed utilizing Grand Teton, our in-house-designed, open GPU {hardware} platform that we’ve contributed to the Open Compute Challenge (OCP). Grand Teton builds on the numerous generations of AI techniques that combine energy, management, compute, and cloth interfaces right into a single chassis for higher total efficiency, sign integrity, and thermal efficiency. It gives fast scalability and suppleness in a simplified design, permitting it to be rapidly deployed into information heart fleets and simply maintained and scaled. Mixed with different in-house improvements like our Open Rack energy and rack structure, Grand Teton permits us to construct new clusters in a manner that’s purpose-built for present and future purposes at Meta.
Now we have been overtly designing our GPU {hardware} platforms starting with our Big Sur platform in 2015.
Storage
Storage performs an necessary function in AI coaching, and but is likely one of the least talked-about facets. Because the GenAI coaching jobs turn into extra multimodal over time, consuming giant quantities of picture, video, and textual content information, the necessity for information storage grows quickly. The necessity to match all that information storage right into a performant, but power-efficient footprint doesn’t go away although, which makes the issue extra fascinating.
Our storage deployment addresses the information and checkpointing wants of the AI clusters by way of a home-grown Linux Filesystem in Userspace (FUSE) API backed by a model of Meta’s ‘Tectonic’ distributed storage solution optimized for Flash media. This resolution allows 1000’s of GPUs to save lots of and cargo checkpoints in a synchronized vogue (a challenge for any storage resolution) whereas additionally offering a versatile and high-throughput exabyte scale storage required for information loading.
Now we have additionally partnered with Hammerspace to co-develop and land a parallel community file system (NFS) deployment to fulfill the developer expertise necessities for this AI cluster. Amongst different advantages, Hammerspace allows engineers to carry out interactive debugging for jobs utilizing 1000’s of GPUs as code modifications are instantly accessible to all nodes throughout the surroundings. When paired collectively, the mix of our Tectonic distributed storage resolution and Hammerspace allow quick iteration velocity with out compromising on scale.
The storage deployments in our GenAI clusters, each Tectonic- and Hammerspace-backed, are primarily based on the YV3 Sierra Point server platform, upgraded with the newest excessive capability E1.S SSD we will procure out there at the moment. Except for the upper SSD capability, the servers per rack was personalized to attain the appropriate steadiness of throughput capability per server, rack rely discount, and related energy effectivity. Using the OCP servers as Lego-like constructing blocks, our storage layer is ready to flexibly scale to future necessities on this cluster in addition to in future, larger AI clusters, whereas being fault-tolerant to day-to-day Infrastructure upkeep operations.
Efficiency
One of many rules we now have in constructing our large-scale AI clusters is to maximise efficiency and ease of use concurrently with out compromising one for the opposite. This is a crucial precept in creating the best-in-class AI fashions.
As we push the bounds of AI techniques, one of the simplest ways we will check our capability to scale-up our designs is to easily construct a system, optimize it, and truly check it (whereas simulators assist, they solely go to date). On this design journey, we in contrast the efficiency seen in our small clusters and with giant clusters to see the place our bottlenecks are. Within the graph under, AllGather collective efficiency is proven (as normalized bandwidth on a 0-100 scale) when a lot of GPUs are speaking with one another at message sizes the place roofline efficiency is predicted.
Our out-of-box efficiency for giant clusters was initially poor and inconsistent, in comparison with optimized small cluster efficiency. To deal with this we made a number of modifications to how our inner job scheduler schedules jobs with community topology consciousness – this resulted in latency advantages and minimized the quantity of site visitors going to higher layers of the community. We additionally optimized our community routing technique together with NVIDIA Collective Communications Library (NCCL) modifications to attain optimum community utilization. This helped push our giant clusters to attain nice and anticipated efficiency simply as our small clusters.
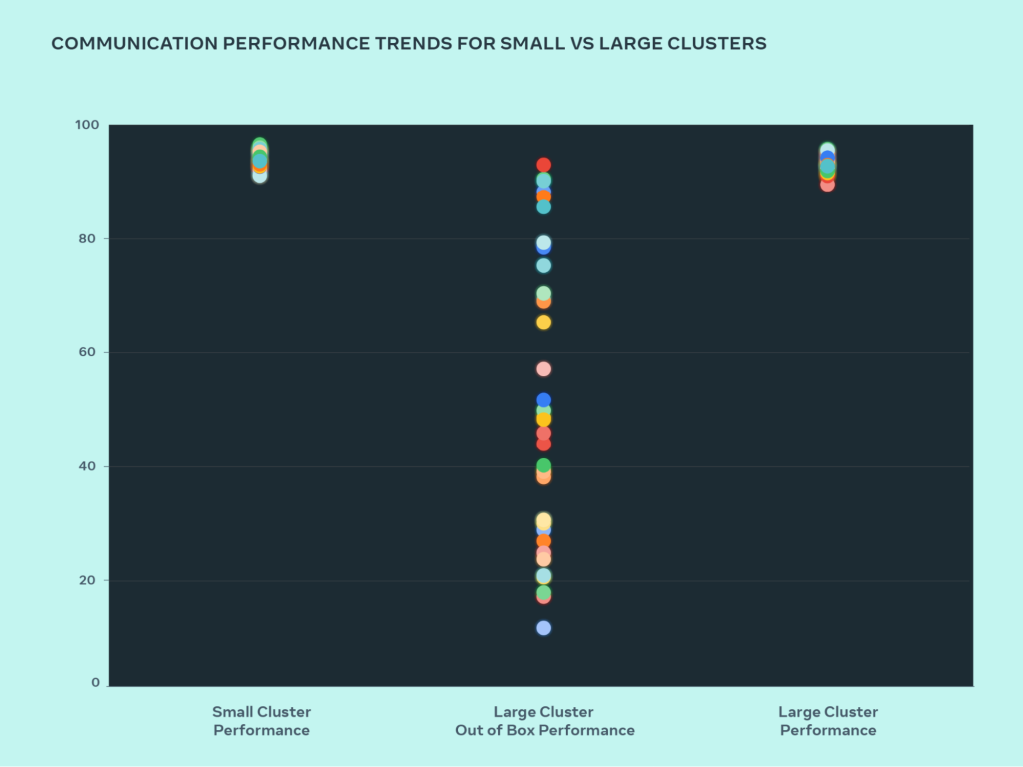
Along with software program modifications concentrating on our inner infrastructure, we labored intently with groups authoring coaching frameworks and fashions to adapt to our evolving infrastructure. For instance, NVIDIA H100 GPUs open the potential of leveraging new information sorts comparable to 8-bit floating level (FP8) for coaching. Totally using bigger clusters required investments in further parallelization methods and new storage options supplied alternatives to extremely optimize checkpointing throughout 1000’s of ranks to run in a whole lot of milliseconds.
We additionally acknowledge debuggability as one of many main challenges in large-scale coaching. Figuring out a problematic GPU that’s stalling a whole coaching job turns into very tough at a big scale. We’re constructing instruments comparable to desync debug, or a distributed collective flight recorder, to show the small print of distributed coaching, and assist determine points in a a lot quicker and simpler manner
Lastly, we’re persevering with to evolve PyTorch, the foundational AI framework powering our AI workloads, to make it prepared for tens, and even a whole lot, of 1000’s of GPU coaching. Now we have recognized a number of bottlenecks for course of group initialization, and decreased the startup time from generally hours right down to minutes.
Dedication to open AI innovation
Meta maintains its dedication to open innovation in AI software program and {hardware}. We consider open-source {hardware} and software program will all the time be a priceless instrument to assist the trade resolve issues at giant scale.
In the present day, we proceed to help open hardware innovation as a founding member of OCP, the place we make designs like Grand Teton and Open Rack obtainable to the OCP neighborhood. We additionally proceed to be the biggest and first contributor to PyTorch, the AI software program framework that’s powering a big chunk of the trade.
We additionally proceed to be dedicated to open innovation within the AI analysis neighborhood. We’ve launched the Open Innovation AI Research Community, a partnership program for tutorial researchers to deepen our understanding of responsibly develop and share AI applied sciences – with a specific concentrate on LLMs.
An open strategy to AI will not be new for Meta. We’ve additionally launched the AI Alliance, a gaggle of main organizations throughout the AI trade centered on accelerating accountable innovation in AI inside an open neighborhood. Our AI efforts are constructed on a philosophy of open science and cross-collaboration. An open ecosystem brings transparency, scrutiny, and belief to AI improvement and results in improvements that everybody can profit from which are constructed with security and duty high of thoughts.
The way forward for Meta’s AI infrastructure
These two AI coaching cluster designs are part of our bigger roadmap for the way forward for AI. By the top of 2024, we’re aiming to proceed to develop our infrastructure build-out that can embody 350,000 NVIDIA H100s as a part of a portfolio that can characteristic compute energy equal to almost 600,000 H100s.
As we glance to the long run, we acknowledge that what labored yesterday or at the moment might not be adequate for tomorrow’s wants. That’s why we’re consistently evaluating and enhancing each facet of our infrastructure, from the bodily and digital layers to the software program layer and past. Our objective is to create techniques which are versatile and dependable to help the fast-evolving new fashions and analysis.
/* */